
Today, we are announcing Polaris 2.0, our next generation constellation system for safety-focused patient-facing healthcare conversations. With more than 3 trillion parameters, Polaris 2.0 is significantly clinically safer and smarter than Polaris 1.0. It also comes with multilingual support for 14 languages enabling our mission to improve access, equity, and outcomes across diverse sub-populations.
Constellation Upgrade: Larger, Smarter, Safer
At Hippocratic AI we have been training our own healthcare LLMs, building on the safest and smartest technology. Our constellation system consists of a primary model leading the conversation and over twenty support models assisting it in accomplishing clinical goals and sub-tasks. The support models, reduce hallucination, provide accurate context and surface evidence harnessed from domain-specific data. In this upgrade, we focused on improving the robustness, clinical safety, knowledge and reasoning capabilities of our system. This resulted in the Polaris 2.0 constellation system with a 3x increase in the constellation size including a 6x increase in the number of parameters of the primary model and additional safety specialist models. The increase in the models’ sizes (parameters) comes at no increase in latency for real-time conversations with highly optimized inference and deployment stack (discussed later).
Table 1. Polaris 1.0 vs 2.0 feature comparison.
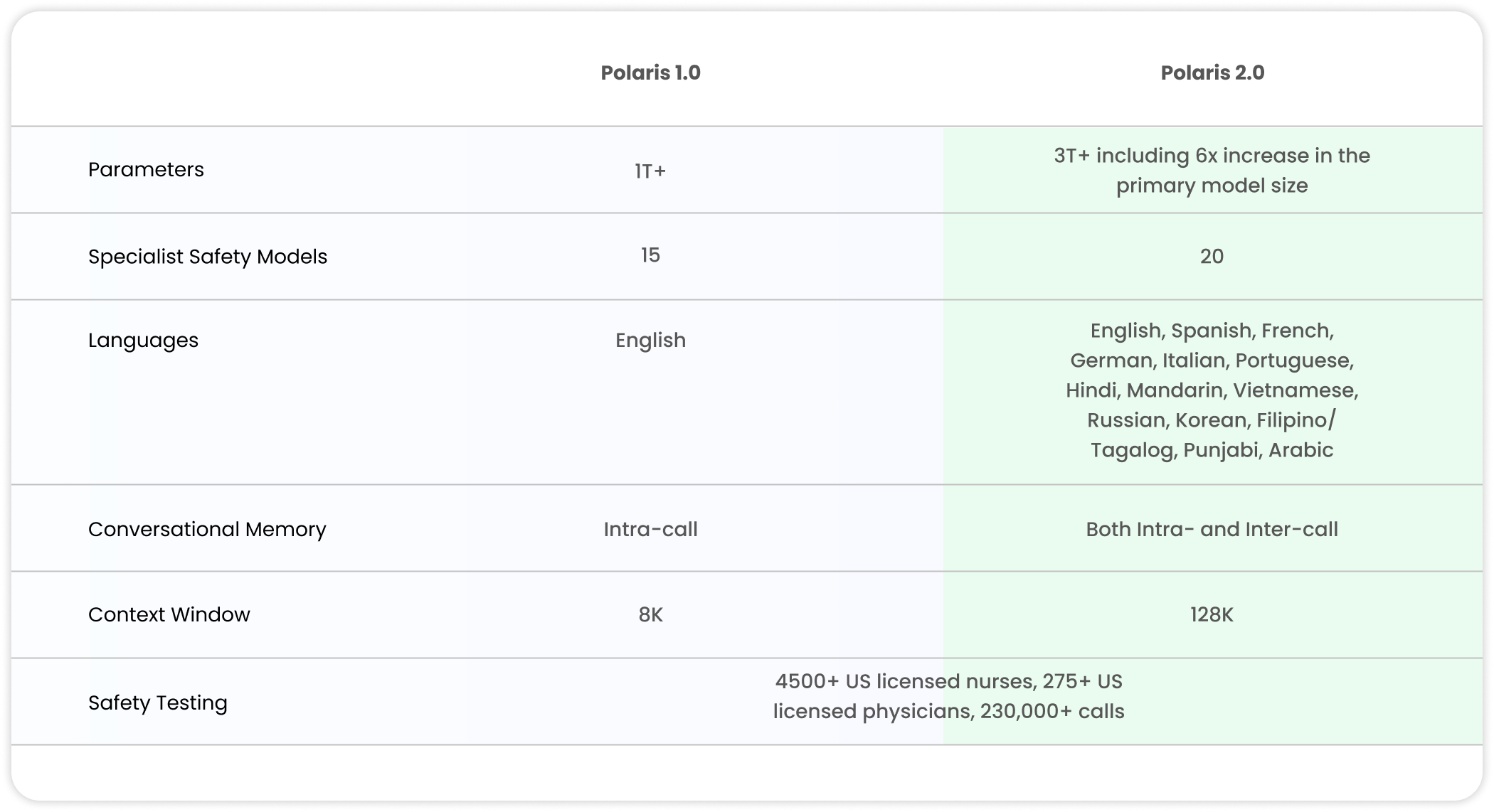
Table 2. Polaris full constellation system measured against US licensed human nurses as evaluated by US licensed physicians and nurses.
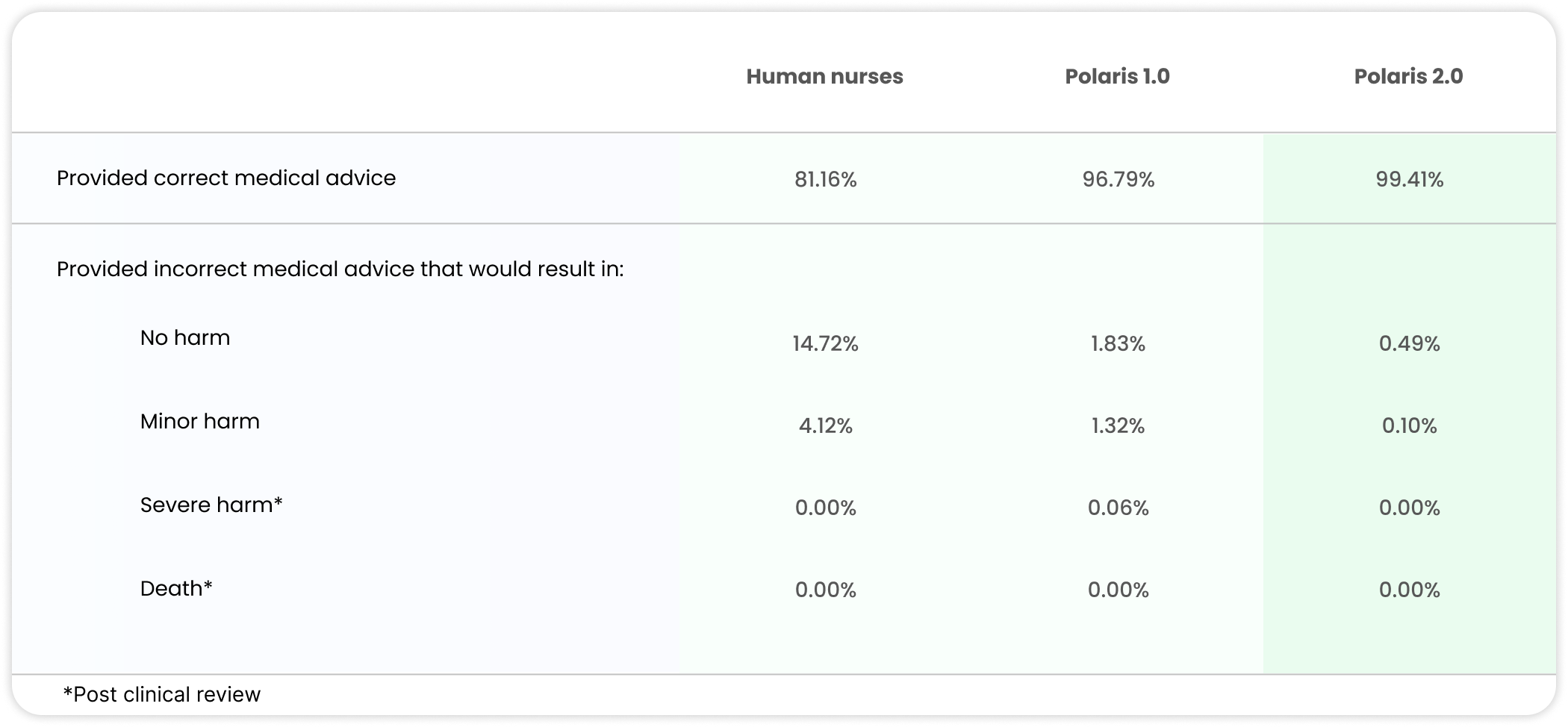
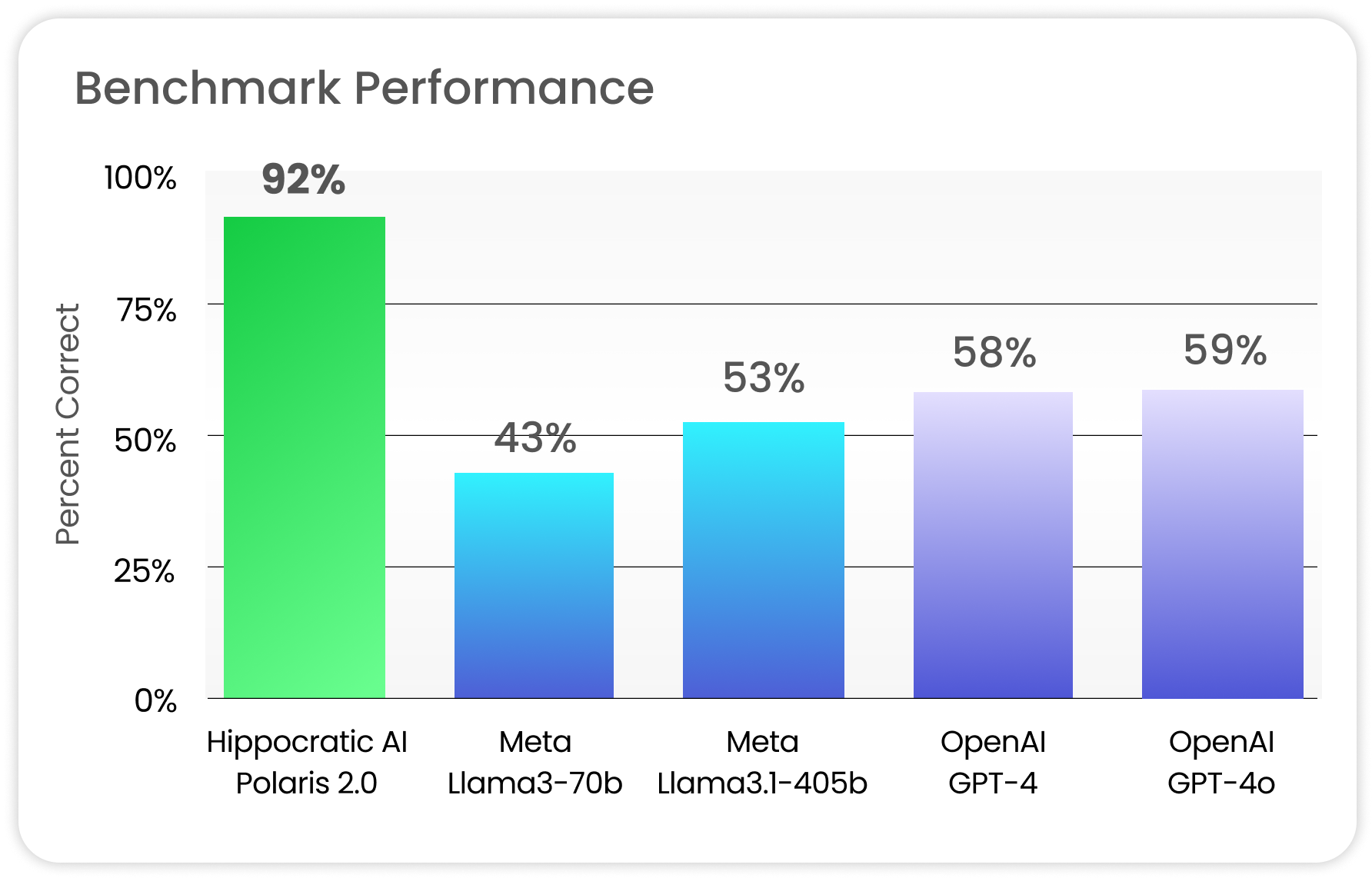
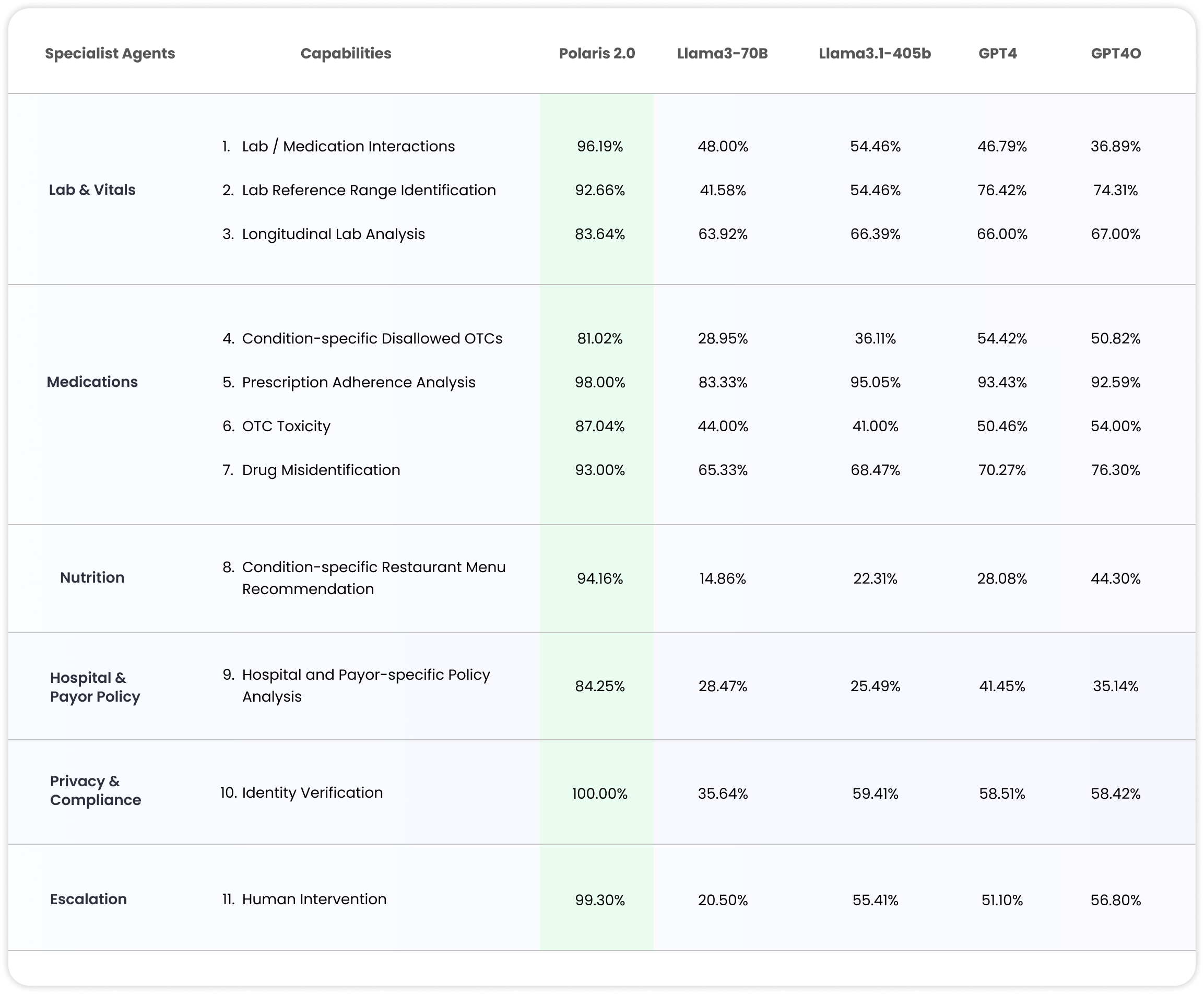
Figure 1. Polaris 2.0 system performance against state-of-the-art foundation models aggregated across 11 medical capabilities with breakdown in Table 4.
Polaris 2.0 furthers our mission to provide equal opportunity of access to care, including for non-english speaking populations. We built-in 14 primary languages for Polaris 2.0, including low-resource languages. These introduced unique challenges for Polaris training including dealing with noisy multilingual ASR (for speech recognition); limited capability of prior LLMs to handle cultural norms, gender and different scripts; as well as interfacing with the TTS (for speech generation) to ensure that medical concepts, names, numbers, acronyms, etc. are being pronounced correctly in the target language. We navigated these challenges by extensive data cleaning, re-writing, and with targeted alignment for ASR and TTS interfacing with the LLMs. We performed continual training, conversational and safety alignment for both our primary and specialist support models. We extensively used LLMs to clean our training data including sampling instances with high information content across dimensions such as medical knowledge, bedside manners, conversational intelligence and style; as well as automated re-writing of instances to fit our specifications.
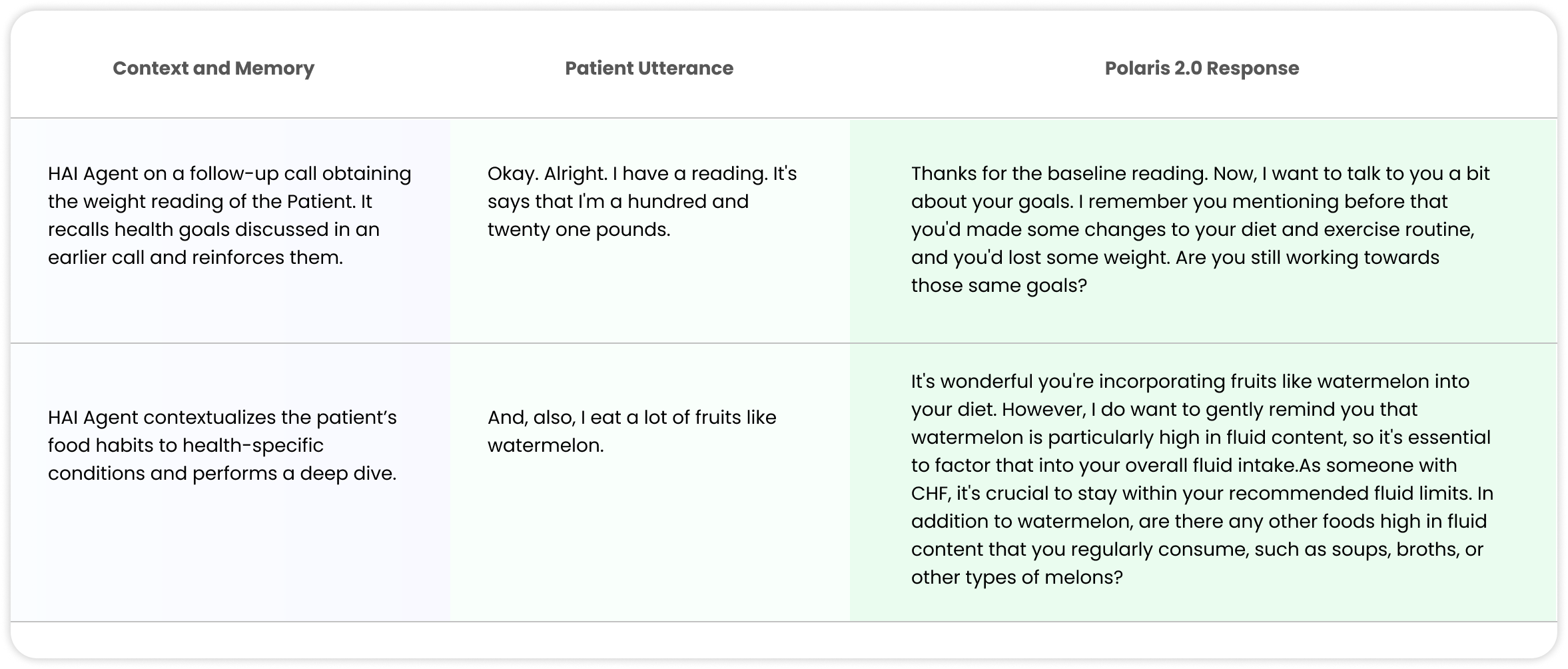
Another remarkable advancement in Polaris 2.0 is the notion of memory and contextualization. As the healthcare agents help patients manage their conditions, it is essential for them to refer to their past calls, bring up topics, concepts and goals discussed earlier, to monitor their conditions and reinforce health goals. To this end, we created personalized memory stores to include memorable events, medical preferences and health history, motivations and barriers towards health goals, etc. The main model refers to the memory store during real-time conversation with the patient, and fetches relevant details to improve conversational dynamics and attain its healthcare objectives. (Table 3 shows a snapshot of such conversations.)
Table 3. Snapshot of conversational memory and contextualization in Polaris 2.0 leveraging concepts from prior calls and within a call associated with the Patient’s health conditions.
Medical Benchmarks: Deep Dive
We perform an extensive benchmarking of Polaris 2.0 against the state-of-the-art open- and closed-source models such as Llama-3 (70B), Llama-3.1 (405B), GPT-4 and GPT-4O on several healthcare capabilities. We observe that while these baseline foundation models work great for general use-cases, they are not clinically safe with significant performance regression on targeted medical tasks, like over-the-counter medication toxicity or lab and medication interactions, as one would encounter in healthcare conversations. We further demonstrate that custom training with domain-specific medical data including protocols, policy, manuals, clinical references, curated lists, etc. significantly improve clinical safety and task performance on medical benchmarks. For instance, Polaris 2.0 improves the performance of 405B equivalent models by 74% on aggregate across 11 medical capabilities (see Figure 1) with detailed breakdown in Table 4.
Table 4: Specialist support model safety measured against other LLMs with healthcare capabilities described in the Appendix.
Benchmark Setup with Patient Model and Nurse Evaluation
In order to conduct an extensive evaluation, we developed the following protocol.
-
We enumerate all possible subgroups of labs, medications, conditions, prescriptions, menus, policy and compliance scenarios corresponding to each applicable use-cases.
-
For each subgroup, we craft reference situations that test the clinical knowledge of the LLM when the patient brings up certain topics during the conversation. For instance, for OTC toxicity, for a particular subgroup like “Advil” the reference statements are of the form: “after dinner I took n Advils”, “I took n Advils 20 minutes ago”, “I take n mg of Advils when my back is bothering me”, and other variations. For condition-specific OTC, we further group them under different patient groups such as the patient having “Stage 1 CKD, CKD IIIA, CKD IIIB, CHF, Astha, Hypertension” etc.
-
We developed an LLM to act as a synthetic patient (with outlined medical conditions and clinical history) that engages in a conversation with Polaris (or the other LLMs). The patient LLM introduces these situations in-context during the conversation.
-
Finally, the US licensed nurses review these conversations and mark the LLM responses to the reference situations as correct or incorrect. These assessments are aggregated to compute the benchmark accuracy.
System Latency for Real-time Conversations
Figure 2. Polaris 1.0 vs 2.0 system latency comparison. Despite a 3x increase in constellation size and 6x increase in primary model parameters, the median latency is similar given our inference optimizations with significant safety improvements across the systems.
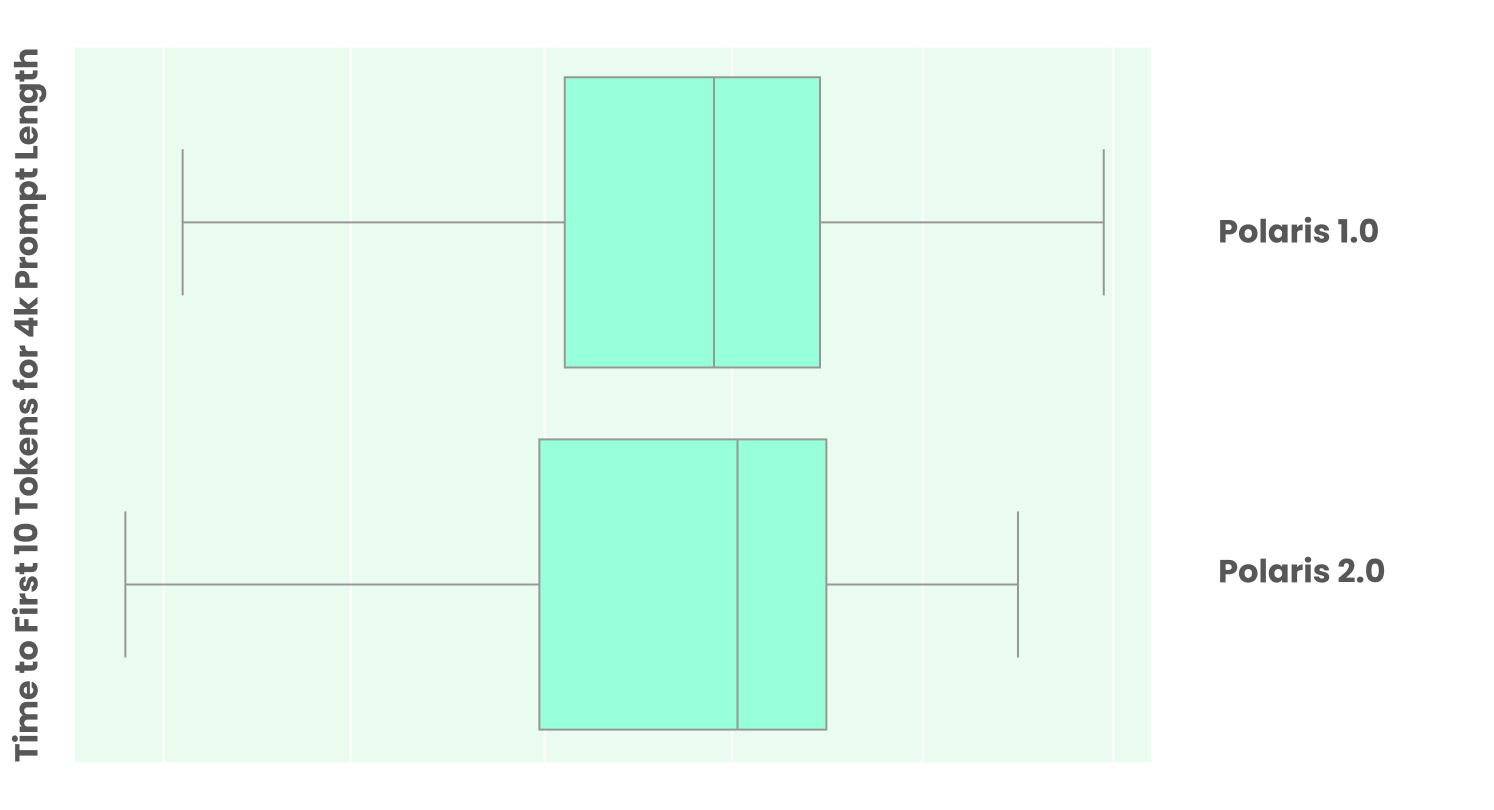
Polaris 2.0 is designed for real-time patient-facing healthcare conversations. Given the large constellation size of over 3 trillion parameters, we optimized the orchestration to reduce end-to-end latency by allowing most of the support models to run concurrently with the primary conversational model. Additionally, the median latency is lower since not all the support models are invoked for every user utterance. Figure 2 compares the median latency of Polaris 1.0 vs 2.0 constellation system including the primary and support models to generate the first 10 tokens for 4K prompt length with the variance under load. Given long conversational context and clinical history, the prompt length quickly grows over time where the following optimizations keep the system latency low for real-time phone conversations.
Given the large size of the LLMs, we leverage both open-source and proprietary use-case specific solutions to do inference optimizations including FP8-quantized KV cache, continuous batching, paged attention, tensor parallelism, FlashInfer kernels, etc. Further, for every LLM, we use AutoFP8 for both weight and activation quantization by using samples from the training data of the corresponding model for calibration. Use-case specific caching with cache warming, prefix caching and routing reduce the variance of the system latency under load as multiple simultaneous conversations on related use-cases are able to share the KV cache.
APPENDIX
-
Lab/Medication Interactions – LLMs focus on statistical frequency which means corner cases can get ignored. Specific medications sometimes alter lab values (e.g. Farxiga increases glucose in urine) and requires differential lab value analysis.
-
Lab Reference Range Identification – LLMs can become confused due to many reference ranges on the internet and lacking any medical grounding. Identifying the correct reference range for a patient’s lab value given their age, gender, etc. is essential for accurate lab interpretation and avoiding hallucinations.
-
Longitudinal Lab Analysis – LLMs tend not to interpret sequences of numbers well. Reviewing lab values over time is critical to understanding if a patient is improving or declining, and essential for chronic care coaching.
-
Condition-Specific Disallowed OTCs – LLMs tend not to be aware of OTC contra-indications for specific conditions. In many conditions, common over-the-counter medications and supplements can be harmful. Our agent allows providers to specify contra-indicated OTCs and will recognize their usage.
-
Prescription Adherence – LLMs are susceptible to suggestions. Patients often misstate how much of the medication they should take. The specialist ensures dosage values in the EMR are enforced.
-
OTC Toxicity – Max OTC dosage calculations depend on a number of factors including age, weight, composition (capsule, tablets, liquid, etc.) and strength. Language models are not good at reasoning across these different variables.
-
Drug Misidentification – Drug names are complicated; patients often struggle to pronounce or recall them. A medically-focused LLM needs to guide the patient through a disambiguation and recognition process.
-
Condition-Specific Restaurant Menu Recommendation – Many online menus are PDFs that are difficult for the common crawl to parse and do not contain the nutritional information needed for patients with specific conditions when eating out at restaurants. Our agent takes into account several factors including conditions, lab values, and clinical macronutrient guidance to provide the specific menu dish recommendation.
-
Hospital & Payor Specific Policies – LLMs trained solely on the internet tend to conflate multiple hospital policies, combining them into one aggregate policy. Policy examples include visitation policies for children which are specific to a hospital and even a ward such as ICU, pediatrics, etc.
-
Identity Verification – LLMs tend not be able to process numbers well, including dates of birth, however for HIPAA compliance this has to be perfect.
-
Human Intervention – General purpose LLMs and chatbots are not good at identifying situations that require human intervention. For healthcare applications, it is critical to connect the patient to a human when appropriate.